السلام عليكم ورحمة الله وبركاته .............
بدخل في الموضوع مباشره ....بنات اللي فاهمه وشاطره وبلبل في اللغة الانجليزيه الله يوفقها تساعدني وربي محتاجة لها
السالفه ومافيه ان اخوي في الجامعه له كم سنه وهو يعيد على مادة وحده صارت مشاكل بينه وبين الدكتور ومن يومها وهو حاقد عليه وربي تعقد من الجامعه ونفس الدكتور قاله اذا بتنجح سو لي بحث ابي اعطيك كم موضوع
وانت اختار واحد منها وسو بحث عاد اخوي مايفهم بالانجليزي مييييييييييييييح وطلب مني اسويله بحث وانا ازفت منه ماعندي سالفه بس دامه طلبني ما حبيت اخذله تكفون عزيزاااااااااتي طالبتكم ساعدوني الله يسعدكم ويفتحها عليكم البحث مطلوب بعد بكره الاربعاء ماعنده فرصه غير بكره اللي عندها خلفيه بالبحوث تساعدني ربي يرزقها وين ماراحت
فيه كم موضوع ..
parallel computers
super computer
superscalar computer
distributed systems
واحد من هالمواضيع مطلوب انه يختاره ويسوي بحث
بنات استنى فزعتكم لاتخيبون ظني ربي يوفقها دنيا واخره
يجزاها ربي كل خير
mohabtteen @mohabtteen
محررة
يلزم عليك تسجيل الدخول أولًا لكتابة تعليق.
mohabtteen
•
بنـــــــــــــــــــــــــــــــــــــــــــــــــــــات تكفون وينكم لاتفشلوني
مااعرف بس تقدرين توكلين شخص يعرف بالبحوث و يبحث لكم بس بفلوس و يعطيكي بحث كامل الله يسر امركم يارب
تومويو
•
والله ودي اساعدك بس هالمواضيع استصعبتها انا .. كلها تخص الكومبيوتر
ان شاء الله تلقين احد يساعدك او شوفي المكتبات اللي تسوي البحوث بمبلغ
ان شاء الله تلقين احد يساعدك او شوفي المكتبات اللي تسوي البحوث بمبلغ
so3
•
حبيبتى اختارى اى موضوع منهم وابحثى عنه فى الجوجل هتلاقى كل المعلومات اللى تحتاجيها وكمان هتلاقى ابحاث منشوره فى النت .. يعنى انا كتبت فى الجوجل parallel computers
لقيت البحث فى الرابط ده
http://en.wikipedia.org/wiki/Parallel_computing
ابحثى عن كذا رابط كمان وبس هيكون عندك بحث متكامل إن شاء الله
وبالتوفيق لكى ولأخوكى
لقيت البحث فى الرابط ده
http://en.wikipedia.org/wiki/Parallel_computing
ابحثى عن كذا رابط كمان وبس هيكون عندك بحث متكامل إن شاء الله
وبالتوفيق لكى ولأخوكى
السلام عليكم والرحمه
اختي بحث لك لين مآلقيت هذآ مع انه عندي اختبآرات بس حبيت اساعدك :)
ان شآء الله يعجبك =)
ولقيت ملف بوربوينت بس مااعرف احمله :44:
دعوآتك لي اختي اني اجيب معدل حلو يفرح امي وابوي
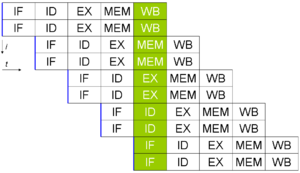
superscalar computer
A superscalar CPU architecture implements a form of parallelism called instruction-level parallelism within a single processor. It thereby allows faster CPU throughput as would otherwise be not possible with the same clock rate. A superscalar processor executes more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to redundant functional units on the processor. Each functional unit is not a separate CPU core but an execution resource within a single CPU such as an arithmetic logic unit, a bit shifter, or a multiplier.
While a superscalar CPU is typically also pipelined, they are two different performance enhancement techniques.
The superscalar technique is traditionally associated with several identifying characteristics. Note these are applied within a given CPU core.
Accepts multiple instructions per clock cycle
History
Seymour Cray's CDC 6600 from 1965 is often mentioned as the first superscalar design. The Intel i960CA (1988) and the AMD 29000-series 29050 (1990) microprocessors were the first commercial single-chip superscalar microprocessors. RISC CPUs like these brought the superscalar concept to microcomputers because the RISC design results in a simple core, allowing straightforward instruction dispatch and the inclusion of multiple functional units (such as ALUs) on a single CPU in the constrained design rules of the time. This was the reason that RISC designs were faster than CISC designs through the 1980s and into the 1990s.
Except for CPUs used in low-power applications, embedded systems, and battery-powered devices, essentially all general-purpose CPUs developed since about 1998 are superscalar.
The Pentium was the first superscalar x86 processor; the Nx586, Pentium Pro and AMD K5 were among the first designs which decodes x86-instructions asynchronously into dynamic microcode-like micro-op sequences prior to actual execution on a superscalar microarchitecture; this opened up for dynamic scheduling of buffered partial instructions and enabled more parallelism to be extracted compared to the more rigid methods used in the simpler Pentium; it also simplified speculative execution and allowed higher clock frequencies compared to designs such as the advanced Cyrix 6x86.
Limitations
Available performance improvement from superscalar techniques is limited by two key areas:
The degree of intrinsic parallelism in the instruction stream, i.e. limited amount of instruction-level parallelism, and
The complexity and time cost of the dispatcher and associated dependency checking logic.
Existing binary executable programs have varying degrees of intrinsic parallelism. In some cases instructions are not dependent on each other and can be executed simultaneously. In other cases they are inter-dependent: one instruction impacts either resources or results of the other. The instructions a = b + c; d = e + f can be run in parallel because none of the results depend on other calculations. However, the instructions a = b + c; b = e + f might not be runnable in parallel, depending on the order in which the instructions complete while they move through the units.
When the number of simultaneously issued instructions increases, the cost of dependency checking increases extremely rapidly. This is exacerbated by the need to check dependencies at run time and at the CPU's clock rate. This cost includes additional logic gates required to implement the checks, and time delays through those gates. Research shows the gate cost in some cases may be nk gates, and the delay cost k2logn, where n is the number of instructions in the processor's instruction set, and k is the number of simultaneously dispatched instructions. In mathematics, this is called a combinatoric problem involving permutations.
Even though the instruction stream may contain no inter-instruction dependencies, a superscalar CPU must nonetheless check for that possibility, since there is no assurance otherwise and failure to detect a dependency would produce incorrect results.
No matter how advanced the semiconductor process or how fast the switching speed, this places a practical limit on how many instructions can be simultaneously dispatched. While process advances will allow ever greater numbers of functional units (e.g, ALUs), the burden of checking instruction dependencies grows so rapidly that the achievable superscalar dispatch limit is fairly small. -- likely on the order of five to six simultaneously dispatched instructions.
However even given infinitely fast dependency checking logic on an otherwise conventional superscalar CPU, if the instruction stream itself has many dependencies, this would also limit the possible speedup. Thus the degree of intrinsic parallelism in the code stream forms a second limitation.
Alternatives
Collectively, these two limits drive investigation into alternative architectural performance increases such as Very Long Instruction Word (VLIW), Explicitly Parallel Instruction Computing (EPIC), simultaneous multithreading (SMT), and multi-core processors.
With VLIW, the burdensome task of dependency checking by hardware logic at run time is removed and delegated to the compiler. Explicitly Parallel Instruction Computing (EPIC) is like VLIW, with extra cache prefetching instructions.
Simultaneous multithreading, often abbreviated as SMT, is a technique for improving the overall efficiency of superscalar CPUs. SMT permits multiple independent threads of execution to better utilize the resources provided by modern processor architectures.
Superscalar processors differ from multi-core processors in that the redundant functional units are not entire processors. A single processor is composed of finer-grained functional units such as the ALU, integer multiplier, integer shifter, floating point unit, etc. There may be multiple versions of each functional unit to enable execution of many instructions in parallel. This differs from a multi-core processor that concurrently processes instructions from multiple threads, one thread per core. It also differs from a pipelined CPU, where the multiple instructions can concurrently be in various stages of execution, assembly-line fashion.
The various alternative techniques are not mutually exclusive—they can be (and frequently are) combined in a single processor. Thus a multicore CPU is possible where each core is an independent processor containing multiple parallel pipelines, each pipeline being superscalar. Some processors also include vector capability.
اختي بحث لك لين مآلقيت هذآ مع انه عندي اختبآرات بس حبيت اساعدك :)
ان شآء الله يعجبك =)
ولقيت ملف بوربوينت بس مااعرف احمله :44:
دعوآتك لي اختي اني اجيب معدل حلو يفرح امي وابوي
superscalar computer
A superscalar CPU architecture implements a form of parallelism called instruction-level parallelism within a single processor. It thereby allows faster CPU throughput as would otherwise be not possible with the same clock rate. A superscalar processor executes more than one instruction during a clock cycle by simultaneously dispatching multiple instructions to redundant functional units on the processor. Each functional unit is not a separate CPU core but an execution resource within a single CPU such as an arithmetic logic unit, a bit shifter, or a multiplier.
While a superscalar CPU is typically also pipelined, they are two different performance enhancement techniques.
The superscalar technique is traditionally associated with several identifying characteristics. Note these are applied within a given CPU core.
- Instructions are issued from a sequential instruction stream
- CPU hardware dynamically checks for
Accepts multiple instructions per clock cycle
History
Seymour Cray's CDC 6600 from 1965 is often mentioned as the first superscalar design. The Intel i960CA (1988) and the AMD 29000-series 29050 (1990) microprocessors were the first commercial single-chip superscalar microprocessors. RISC CPUs like these brought the superscalar concept to microcomputers because the RISC design results in a simple core, allowing straightforward instruction dispatch and the inclusion of multiple functional units (such as ALUs) on a single CPU in the constrained design rules of the time. This was the reason that RISC designs were faster than CISC designs through the 1980s and into the 1990s.
Except for CPUs used in low-power applications, embedded systems, and battery-powered devices, essentially all general-purpose CPUs developed since about 1998 are superscalar.
The Pentium was the first superscalar x86 processor; the Nx586, Pentium Pro and AMD K5 were among the first designs which decodes x86-instructions asynchronously into dynamic microcode-like micro-op sequences prior to actual execution on a superscalar microarchitecture; this opened up for dynamic scheduling of buffered partial instructions and enabled more parallelism to be extracted compared to the more rigid methods used in the simpler Pentium; it also simplified speculative execution and allowed higher clock frequencies compared to designs such as the advanced Cyrix 6x86.
Limitations
Available performance improvement from superscalar techniques is limited by two key areas:
The degree of intrinsic parallelism in the instruction stream, i.e. limited amount of instruction-level parallelism, and
The complexity and time cost of the dispatcher and associated dependency checking logic.
Existing binary executable programs have varying degrees of intrinsic parallelism. In some cases instructions are not dependent on each other and can be executed simultaneously. In other cases they are inter-dependent: one instruction impacts either resources or results of the other. The instructions a = b + c; d = e + f can be run in parallel because none of the results depend on other calculations. However, the instructions a = b + c; b = e + f might not be runnable in parallel, depending on the order in which the instructions complete while they move through the units.
When the number of simultaneously issued instructions increases, the cost of dependency checking increases extremely rapidly. This is exacerbated by the need to check dependencies at run time and at the CPU's clock rate. This cost includes additional logic gates required to implement the checks, and time delays through those gates. Research shows the gate cost in some cases may be nk gates, and the delay cost k2logn, where n is the number of instructions in the processor's instruction set, and k is the number of simultaneously dispatched instructions. In mathematics, this is called a combinatoric problem involving permutations.
Even though the instruction stream may contain no inter-instruction dependencies, a superscalar CPU must nonetheless check for that possibility, since there is no assurance otherwise and failure to detect a dependency would produce incorrect results.
No matter how advanced the semiconductor process or how fast the switching speed, this places a practical limit on how many instructions can be simultaneously dispatched. While process advances will allow ever greater numbers of functional units (e.g, ALUs), the burden of checking instruction dependencies grows so rapidly that the achievable superscalar dispatch limit is fairly small. -- likely on the order of five to six simultaneously dispatched instructions.
However even given infinitely fast dependency checking logic on an otherwise conventional superscalar CPU, if the instruction stream itself has many dependencies, this would also limit the possible speedup. Thus the degree of intrinsic parallelism in the code stream forms a second limitation.
Alternatives
Collectively, these two limits drive investigation into alternative architectural performance increases such as Very Long Instruction Word (VLIW), Explicitly Parallel Instruction Computing (EPIC), simultaneous multithreading (SMT), and multi-core processors.
With VLIW, the burdensome task of dependency checking by hardware logic at run time is removed and delegated to the compiler. Explicitly Parallel Instruction Computing (EPIC) is like VLIW, with extra cache prefetching instructions.
Simultaneous multithreading, often abbreviated as SMT, is a technique for improving the overall efficiency of superscalar CPUs. SMT permits multiple independent threads of execution to better utilize the resources provided by modern processor architectures.
Superscalar processors differ from multi-core processors in that the redundant functional units are not entire processors. A single processor is composed of finer-grained functional units such as the ALU, integer multiplier, integer shifter, floating point unit, etc. There may be multiple versions of each functional unit to enable execution of many instructions in parallel. This differs from a multi-core processor that concurrently processes instructions from multiple threads, one thread per core. It also differs from a pipelined CPU, where the multiple instructions can concurrently be in various stages of execution, assembly-line fashion.
The various alternative techniques are not mutually exclusive—they can be (and frequently are) combined in a single processor. Thus a multicore CPU is possible where each core is an independent processor containing multiple parallel pipelines, each pipeline being superscalar. Some processors also include vector capability.

الصفحة الأخيرة